About a week or two ago, I discovered that one of the five 2TB hard disks in my home network server had… vanished. The system was recognising it as an approximately 3G disk, with no health status, and generally no idea what it was doing.
Needless to say, the storage pool wasn’t the happiest of things, and generally the entire system was almost unresponsive.
When I finally got into the OS, I discovered that one disk (disk 5; the failed one) was in a state of ¯\_(ツ)_/¯, one disk was failing, and another disk was showing warnings
Naturally, the first disk I replaced was disk 5, as I couldn’t get anything out of that at all – connecting it to my PC to try and figure out what was going on caused sufficient disruption to my SATA controller that all other disks vanished from the UEFI configuration tool, but would still start a boot into Windows, which just hung completely. Removal of this disk put the system back to how it was immediately.
This led me to think it was a controller failure – and as my last disk to fail was also a Seagate disk of the same model, I considered doing a quick controller-swap to see if it was indeed a controller failure, but alas no. The “new” controller from the other disk exhibited the exact same symptoms.
Time to open it up!

Dark marks within the seal on the top cover
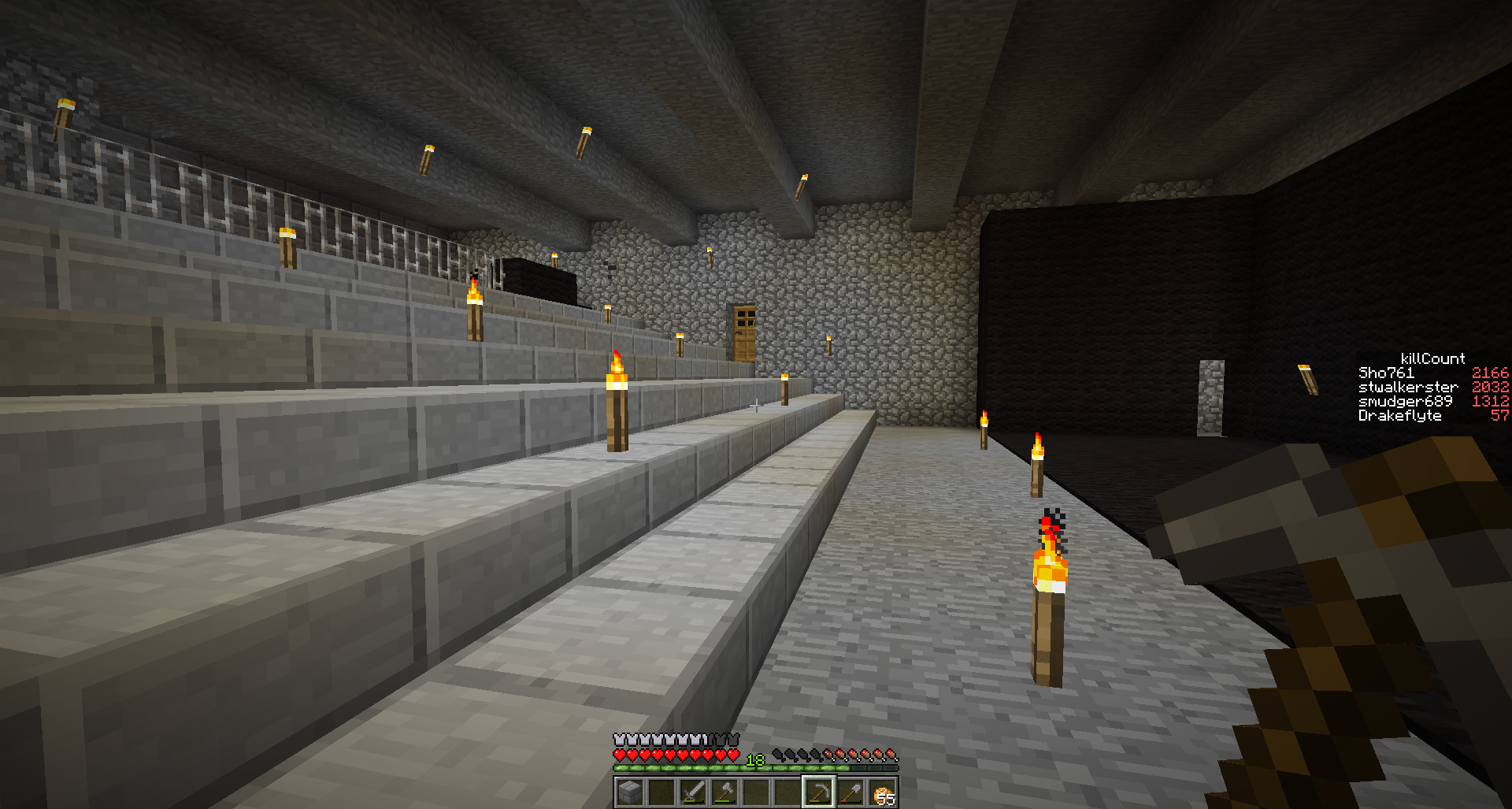
On first opening the drive, I noticed some dark marks on the lid of the drive, indicating that the internals of the drive were not the clean environment I would expect from a drive.
I also noticed some larger debris on the top platter of the disk – not as visible in the photo due to the presence of dust too – it took me a minute to realise I wanted photos of this and to find my camera. Notably, in contrast to everything else, the debris here is actually the larger bits.

Debris on the platter
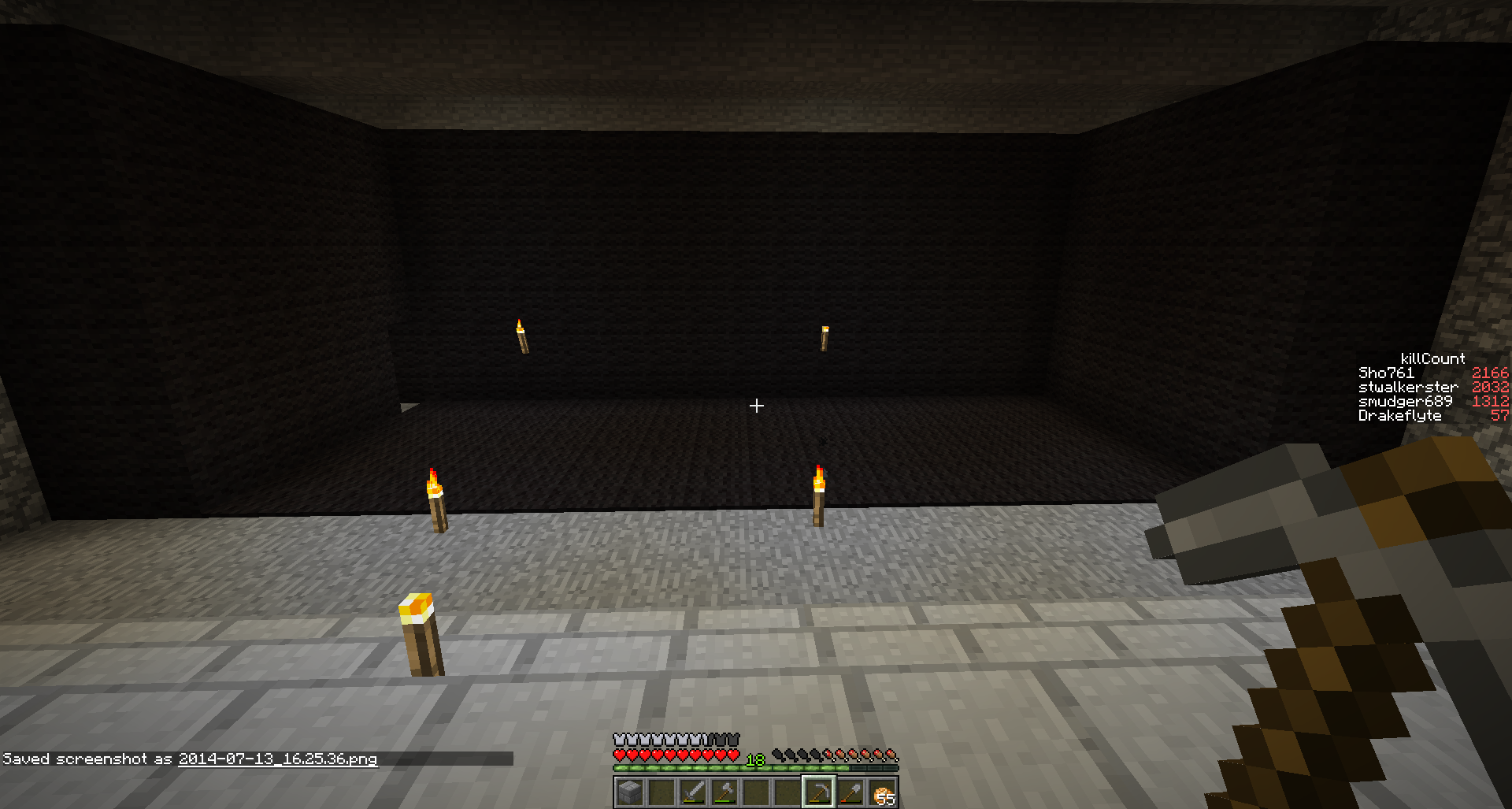
One of the first things I noticed was that the little filter pad to the side of the disk was filthy with the same black marks as the lid of the drive, quickly followed by me noticing a read head was missing from the arm – more noticeable if the arm is swung onto the platters


More debris towards the back of the platter – note the missing read head

Obvious missing read head is obvious
It was also at this point that I noticed the surfaces inside the disk were horribly filthy as well, and I realised that this is a fine likely metallic powder.

Detail of obviously missing read head

Head parking – also covered in the powder
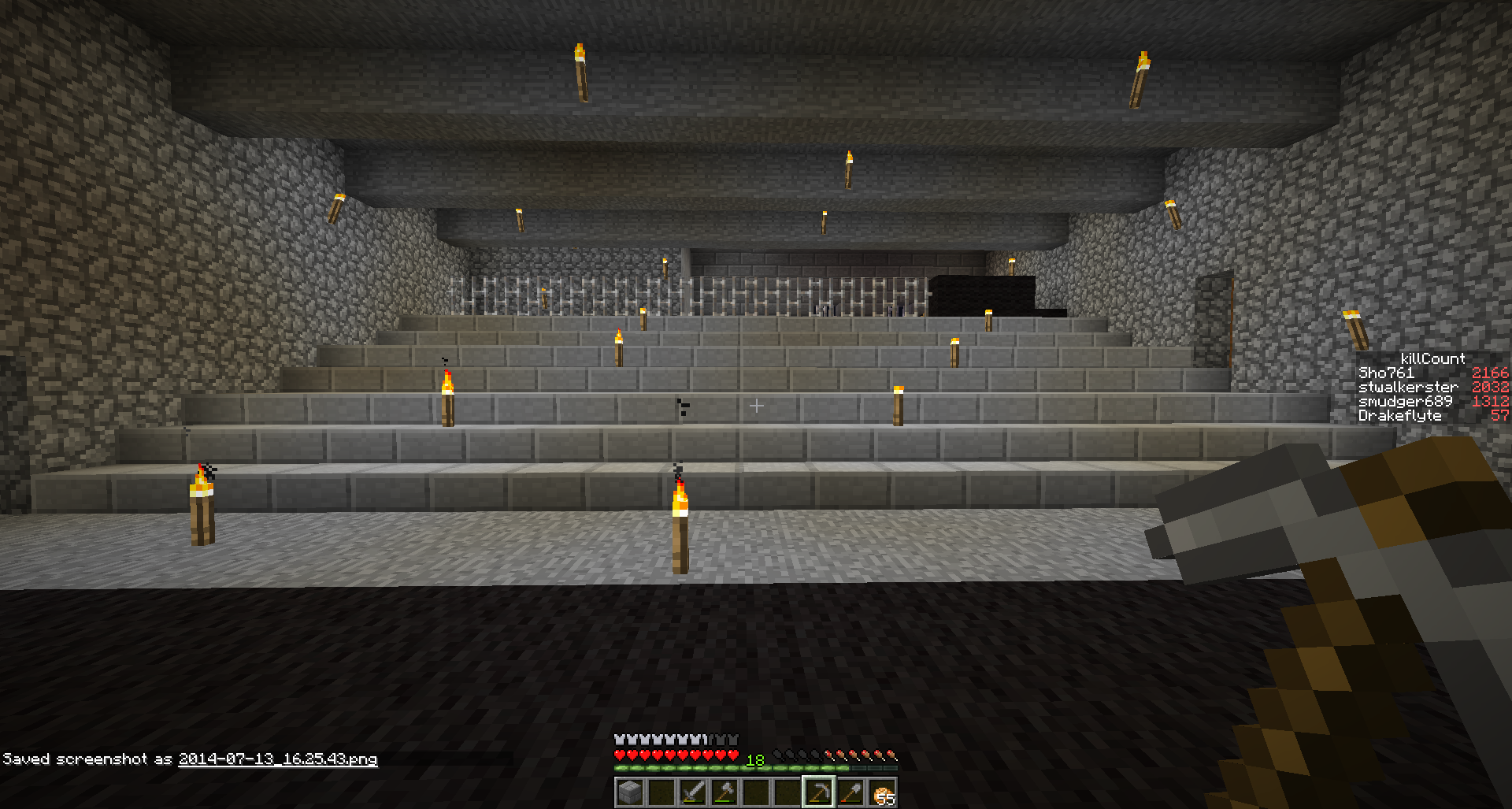
I began to disassemble the stack of platters, in the hope of finding this missing read head, and possibly more insight into what actually happened.
Removal of the retaining bracket at the top of the platter showed how filthy even the surface of the platter is

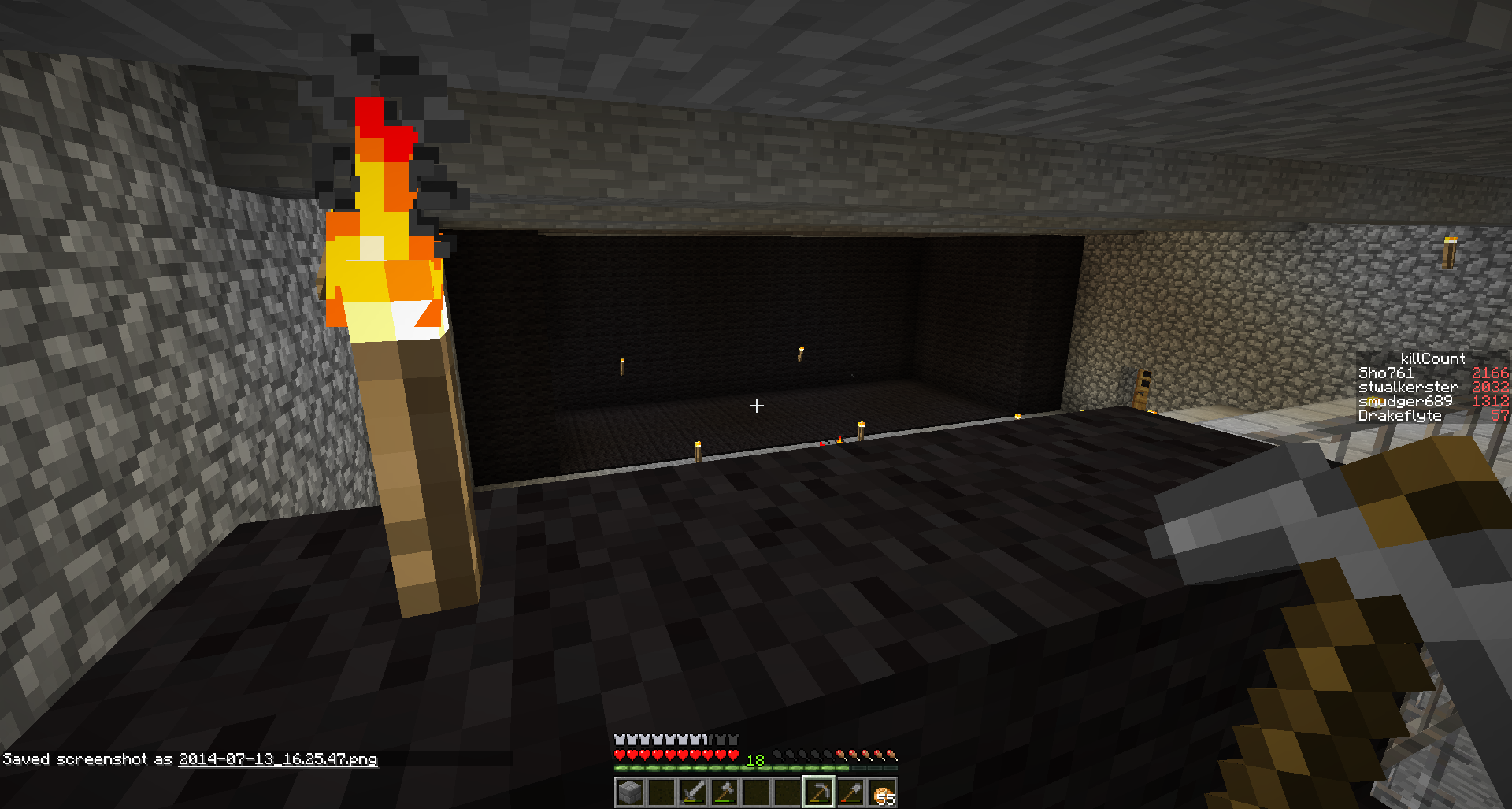
It didn’t take long to find out what happened – the underside of the top platter revealed this pretty patterns of dust, visible on the outer half of the platter still in the case, along with a very obvious wide scratch mark across the surface around the middle.

The next platter down revealed even more dust, along with a massive gouge near the centre of the disk – some serious force must have been involved in this. The entire surface of these platters is also covered in concentric rings of dust which just wipe clean


Needless to say, I think I have a fairly good idea why the drive failed, but there is still one mystery I’ve not solved – where did that read head go to?
For comparison, here’s a photo of another Seagate drive of the same model that also failed (nowhere near as spectacularly) about six months prior – the top read head is clearly visible

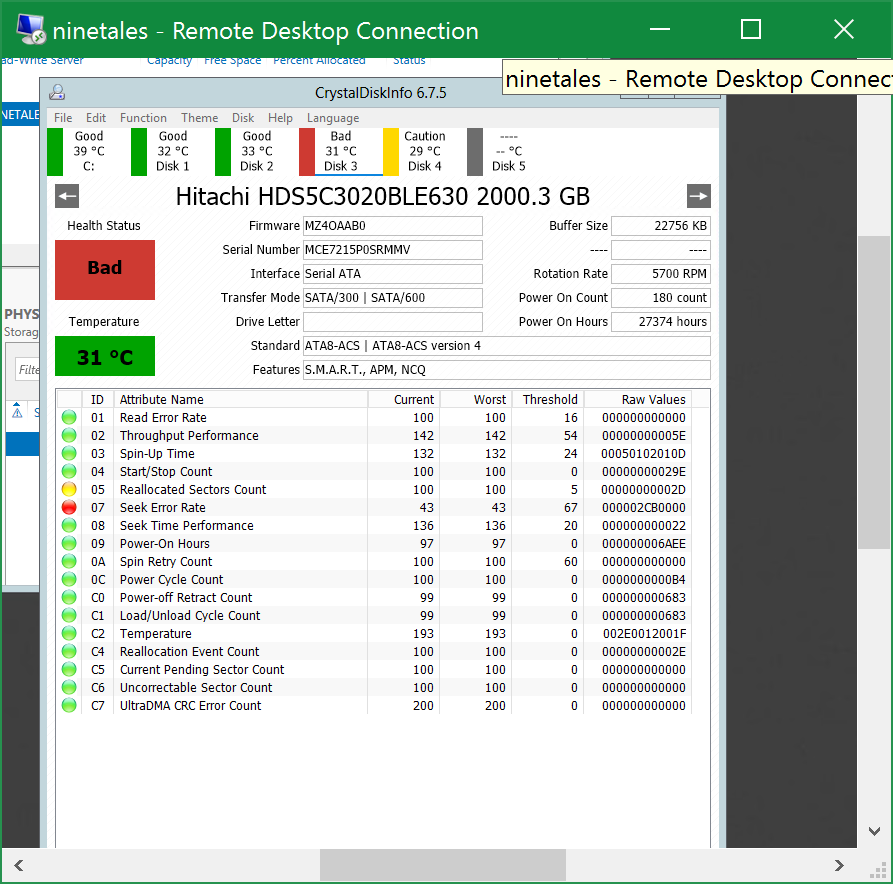
Another curious point is that upon replacement of this disk, the other disk that was reported as bad is suddenly only showing caution signs:

It’s possible that the disruption to the SATA bus was causing this to completely go haywire I suppose, that and the three disks with problems were all in the same cage – so it’s possible that one failing disk has caused issues with the others.

The cage to the rear, behind the memory modules, is the one which caused issues. The disk in question was at the bottom of this cage.