As part of my analysis of the DNS protocol (I’m writing a DNS server from the ground up), I’ve learnt some cool things that the DNS protocol does to reduce the number of bytes transmitted over the wire.
Let’s say you do a DNS lookup for:
stwalkerster.co.uk. IN AAAA
The actual DNS data received as a response is something like this:
Transaction ID: 0x707c
Flags: 0x0100 Standard query response, No error
1... .... .... .... = Response: Message is a response
.000 0... .... .... = Opcode: Standard query (0)
.... .0.. .... .... = Authoritative: Server is not an authority for domain
.... ..0. .... .... = Truncated: Message is not truncated
.... ...1 .... .... = Recursion desired: Do query recursively
.... .... 1... .... = Recursion available: Server can do recursive queries
.... .... .0.. .... = Z: reserved (0)
.... .... ..0. .... = Answer authenticated: Answer/authority portion was not authenticated
.... .... ...0 .... = Non-authenticated data: Unacceptable
.... .... .... 0000 = Reply code: No error (0)
Questions: 1
Answer RRs: 1
Authority RRs: 0
Additional RRs: 0
Queries
stwalkerster.co.uk: type AAAA, class IN
Name: stwalkerster.co.uk
Type: AAAA (IPv6 address)
Class: IN (0x0001)
Answers
stwalkerster.co.uk: type AAAA, class IN, addr 2a01:7e00::f03c:91ff:feae:5fd9
Name: stwalkerster.co.uk
Type: AAAA (IPv6 address)
Class: IN (0x0001)
Time to live: 1 hour
Data length: 16
Addr: 2a01:7e00::f03c:91ff:feae:5fd9
… or at least, that’s a marked-up representation the actual byte stream. The actual byte stream looks like this (Ethernet/IP/UDP headers hidden for clarity):
0000 .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ................
0010 .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. ................
0020 .. .. .. .. .. .. .. .. .. .. 70 7c 81 80 00 01 ..........p|....
0030 00 01 00 00 00 00 0c 73 74 77 61 6c 6b 65 72 73 .......stwalkers
0040 74 65 72 02 63 6f 02 75 6b 00 00 1c 00 01 c0 0c ter.co.uk.......
0050 00 1c 00 01 00 00 0e 10 00 10 2a 01 7e 00 00 00 ..........*.~...
0060 00 00 f0 3c 91 ff fe ae 5f d9 ...<...._.
The interesting part is that you can see the looked up name appearing twice in the human-readable form, but only once in the actual byte stream. To describe why, we need to look at how labels (or names) are stored within the protocol.
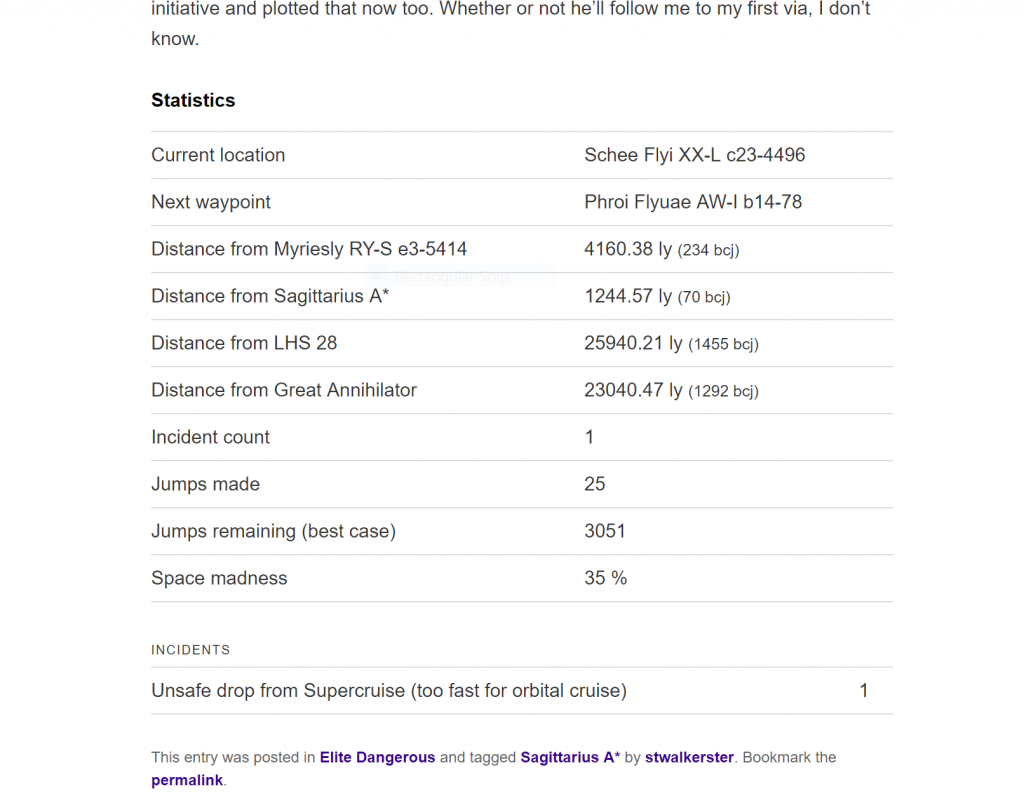
Let's start at a point in the byte stream which is the location of a label. The position I'm gonna look at is byte 0x37, which has the value 0x0c (0d12). This tells us to look for another 12 bytes, which forms this segment of the label. If we read this in, we get "stwalkerster". We now read in the next length byte, which is 0x02 (0d2). This gives us a segment of "co". The next length is also 0x02, which gives us "uk". Finally, we read in the next length (we don't know this is the end yet!), which gives us a length of 0x00, a zero-length label. This is the end of the label.
Thus, the final result is something like this:

The next instance of this label is at 0x4e. We notice that the first byte has the initial two bits set, so we read the next byte too, to give a value of: 0b1100 0000 0000 1100. The first two bits indicate that this is a pointer, with the rest of the bits indicating the offset from the start of the DNS byte stream the occurrence of the label.
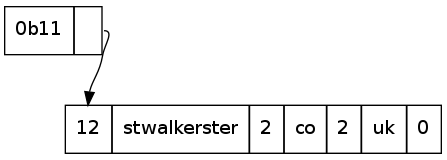
The DNS packet is therefore compressed in such a way that the duplication of the parts of the label already mentioned is eliminated. This is smart, so a packet containing labels for stwalkerster.co.uk, www.stwalkerster.co.uk, test.www.stwalkerster.co.uk, and simonwalker.me.uk will only mention the suffix of a name once:
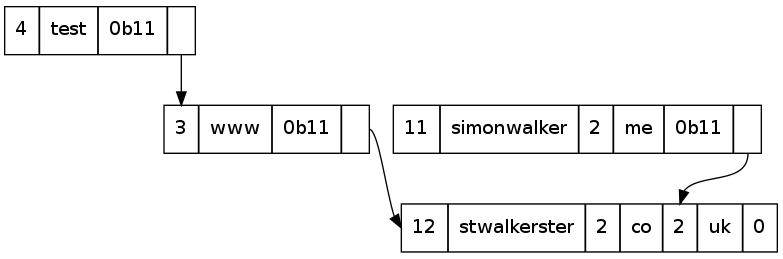
This pointer-based approach saves a fair amount of bandwidth in large DNS packets where a name may be repeated many times for a round-robin type record.
There are some issues with specific implementations of this though, namely the restrictions on where a pointer may point. Consider this:
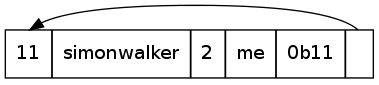
What is the label interpreted by this? simonwalker.me.simonwalker.me.simonwalker.me.simonwalker.me.....
In some bad implementations, this may cause a stack overflow (if done recursively, like mine), or just hang (stuck in an infinite loop, possibly eating RAM). Voila, Denial of Service attack. This can take several forms though, as there could be several pointers involved:
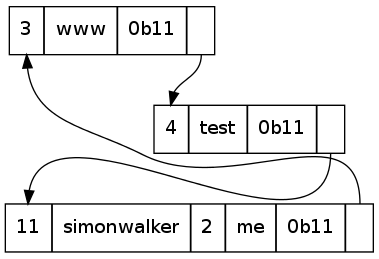
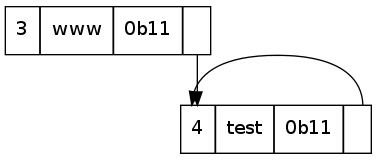
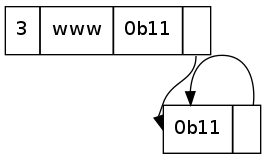
All of the above are technically valid labels. They will just almost never appear as a legitimate request to a DNS server. Any attempt to do something like that should be interpreted as a bad request, or a malicious request and dropped. It shouldn't result in a crash of the DNS server - but I do wonder how many Internet DNS servers are vulnerable to this.